
Latest Event Updates
How to Create Word Count MapReduce Application using Eclipse
In this post, you will create WordCount Application using MapReduce Programming Model. Workflow diagram of WordCount Application is given below.

Steps to run WordCount Application in Eclipse
step-1
Download eclipse if you don’t have. 64 bit Linux os 32 bit Linux os
step-2
Open Eclipse and Make Java Project.
In eclipse Click on File menu-> new -> Java Project. Write there your project name. Here is WordCount. Make sure Java version must be 1.6 and above. Click on Finish.

Step-3
Make Java class File and write a code.
Click on WordCount project. There will be ‘src’ folder. Right click on ‘src’ folder -> New -> Class. Write Class file name. Here is Wordcount. Click on Finish.

Copy and Paste below code in Wordcount.java. Save it.
You will get lots of error but don’t panic. It is because of requirement of external library of hadoop which is required to run mapreduce program.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Wordcount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Step-4
Add external libraries from hadoop.
Right click on WordCount Project -> Build Path -> Configure Build Path -> Click on Libraries -> click on ‘Add External Jars..’ button.

Select below files from hadoop folder.
In my case:- /usr/local/hadoop/share/hadoop

4.1 Add jar files from /usr/local/hadoop/share/hadoop/common folder.

4.2 Add jar files from /usr/local/hadoop/share/hadoop/common/lib folder.

4.3 Add jar files from /usr/local/hadoop/share/hadoop/mapreduce folder (Don’t need to add hadoop-mapreduce-examples-2.7.3.jar)

4.4 Add jar files from /usr/local/hadoop/share/hadoop/yarn folder.

Click on ok. Now you can see, all error in code is gone. 🙂
Step 5
Running Mapreduce Code.
5.1 Make input file for WordCount Project.
Right Click on WordCount project-> new -> File. Write File name and click on ok. You can copy and paste below contains into your input file.
car bus bike bike bus aeroplane truck car bus

5.2 Right click on WordCount Project -> click on Run As. -> click on Run Configuration…
Make new configuration by clicking on ‘new launch configuration’. Set Configuration Name, Project Name and Class file name.

5.3 click on Arguments tab. Write there input and output path.
If you have save above file, write below paths into Program Arguments of arguments tab and click on run.
input out

Output of WordCount Application and output logs in console.
Refresh WordCount Project. Right Click on project -> click on Refresh. You can find ‘out’ directory in project explorer. Open ‘out’ directory. There will be ‘part-r-00000’ file. Double click to open it.

Free Online Courses on Deep Learning
1. Machine Learning – Stanford by Andrew Ng in Coursera
2. Machine Learning – Big Data Univeristy
3. Neural Networks for Machine Learning – by Geoffrey Hinton
4. Neural Network by Hugo Larochelle
5. Deep Learning – Big Data University
6. Deep Learning with tensorflow – Big Data University
7. Bay area DL school by Andrew Ng, Yoshua Bengio, Samy Bengio, Andrej Karpathy, Richard Socher, Hugo Larochelle and many others @ Stanford, CA (2016)
8. Convolutional Neural Networks for Visual Recognition by Fei-Fei Li, Andrej Karpathy (2015) @ Stanford
9. Convolutional Neural Networks for Visual Recognition by Fei-Fei Li, Andrej Karpathy (2016) @ Stanford
10. Deep Learning – Udacity/Google
For More Detials..Click here
How to install TensorFlow in ubuntu 16.04
In this post, you will install TensorFlow in Ubuntu 16.04 LTS 64 bit OS. But following steps are also worked in Ubuntu 14.04 64 bit os.
TensorFlow is an open-source software library for Machine Intelligence.
Python is already installed in Ubuntu. So no need to install again. If you want to check version of installed python, you can use following command.
$ python --version
Following steps are for installing TensorFlow using Python 2.7:
Step: 1
$ sudo apt-get install python-pip python-dev
Step: 2
$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp27-none-linux_x86_64.whlStep: 3
$ sudo pip install --upgrade $TF_BINARY_URL
Test your installation
$ python
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, Parth!')
>>> sess = tf.Session()
>>> print(sess.run(hello))
Hello, Parth!
>>> a = tf.constant(10)
>>> b = tf.constant(20)
>>> print(sess.run(a + b))
30
Configuration of Python Editor for TensorFlow
1. Download PyCharm editor from below link. (Download community edition)
https://www.jetbrains.com/pycharm/download/#section=linux
2. Unpack the PyCharm Community Edition distribution archive that you downloaded to where you wish to install the program. We will refer to this destination location as your {installation home} below.
3. Open a console and cd into “{installation home}/bin” and type:
./pycharm.sh
to start the application.
4. Once it is installed, for reuse you can search PyCharm or you can set icon in quick launcher.
Your First TensorFlow Program in PyCharm Editor
1. Open PyCharm Editor
2. Create New Project
3. Right Click on Project, Go to new -> select ‘Python File’ -> Give file name
4. Copy below code
import tensorflow as tf hello = tf.constant('Hello, Parth!') a = tf.constant(30) b = tf.constant(50) # Start tf session sess = tf.Session() # Run the op print(sess.run(hello)) print(sess.run(a+b))
5. Go to ‘Run’ -> click on ‘Run..’ -> select ‘Your given file name’

How to install hadoop 2.7.3 single node cluster on ubuntu 16.04
In this post, we are installing Hadoop-2.7.3 on Ubuntu-16.04 OS. Followings are step by step process to install hadoop-2.7.3 as a single node cluster.
Before installing or downloading anything, It is always better to update using following command:
$ sudo apt-get update
Step 1: Install Java
$ sudo apt-get install default-jdk
We can check JAVA is properly installed or not using following command:
$ java –version

Step 2: Add dedicated hadoop user
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
NOTE: don’t write password or any things here, Just press ‘y’ when it ask “Is the information correct?[Y|n]”

$ sudo adduser hduser sudo
Step 3: Install SSH
$ sudo apt-get install ssh
Step-4: Passwordless entry for localhost using SSH
$ su hduser

Now we are logined in in ‘hduser’.
$ ssh-keygen -t rsa
NOTE: Leave file name and other things blank.
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
$ ssh localhost

Use above command and make sure it is passwordless login. Once we are logined in localhost, exit from this session using following command
$ exit
Step 5: Install hadoop-2.7.3
$ wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
$ tar xvzf hadoop-2.7.3.tar.gz
$ sudo mkdir -p /usr/local/hadoop
$ cd hadoop-2.7.3/
$ sudo mv * /usr/local/hadoop
$ sudo chown -R hduser:hadoop /usr/local/hadoop
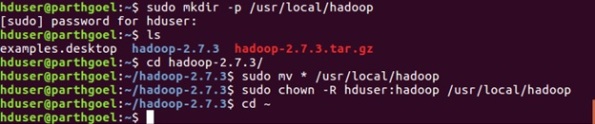
Step 6: Setup Configuration Files
The following files should to be modified to complete the Hadoop setup:
6.1 ~/.bashrc
6.2 hadoop-env.sh
6.3 core-site.xml
6.4 mapred-site.xml
6.5 hdfs-site.xml
6.6 yarn-site.xml
6.1 ~/.bashrc
First, we need to find the path where JAVA is installed in our system
$ update-alternatives --config java

Now we append at the end of ~/.bashrc:
It may possible vi will not work properly. If it does install vim
$ sudo apt-get install vim
Open bashrc file using command:
$ vim ~/.bashrc
Append following at the end. (Follow this process -> First append below content at the end by pressing ‘INSERT’ or ‘i’ key from keyboard-> Press ‘ecs’ -> Press ‘:’ (colon) -> Press ‘wq’->Press ‘Enter’ Key)
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#HADOOP VARIABLES END
Update .bashrc file to apply changes
$ source ~/.bashrc
6.2 hadoop-env.sh
We need to modify JAVA_HOME path in hadoop-env.sh to ensure that the value of JAVA_HOME variable will be available to Hadoop whenever it is started up.
$ vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Search JAVA_HOME variable in file. It may first variable in file. Do Change it by following:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
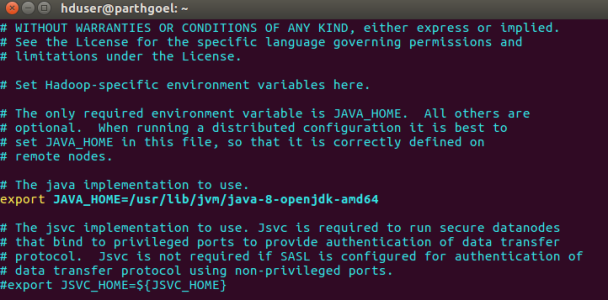
6.3 core-site.xml
core-site.xml file has configuration properties which are requires when Hadoop is started up.
$ sudo mkdir -p /app/hadoop/tmp
$ sudo chown hduser:hadoop /app/hadoop/tmp
Open the file and enter the following in between the tag:
$ vim /usr/local/hadoop/etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
</property>

6.4 mapred-site.xml
By default, the /usr/local/hadoop/etc/hadoop/ folder contains /usr/local/hadoop/etc/hadoop/mapred-site.xml.template file which has to be renamed/copied with the name mapred-site.xml:
$ cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
The /usr/local/hadoop/etc/hadoop/mapred-site.xml file is used to specify which framework is being used for MapReduce.
We need to enter the following content in between the tag:
$ vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

6.5 hdfs-site.xml
We need to configure hdfs-site.xml for each host in the cluster which specifies two directories:
- Name node
- Data node
These can be done using the following commands:
$ sudo mkdir -p /usr/local/hadoop_store/hdfs/namenode
$ sudo mkdir -p /usr/local/hadoop_store/hdfs/datanode
$ sudo chown -R hduser:hadoop /usr/local/hadoop_store
Open hdfs-site.xml file and enter the following content in between the tag:
$ vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/datanode</value>
</property>

6.6 yarn-site.xml
Open hdfs-site.xml file and enter the following content in between the tag:
$ vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>

Step7: Format hadoop file system
$ hadoop namenode –format

Step 8: Start Hadoop Daemons
$ cd /usr/local/hadoop/sbin
$ start-all.sh

We can check all daemons are properly started using following command:
$ jps

Step 9: Stop hadoop Daemons
$ stop-all.sh
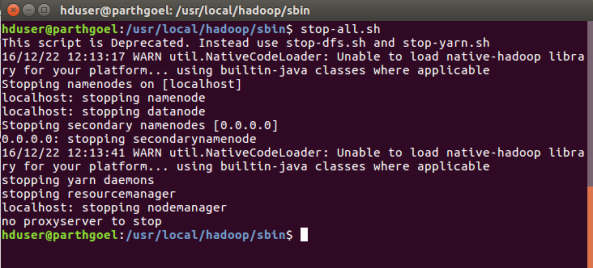
Congratulation..!! We have installed hadoop successfully.. 🙂
Hadoop has Web Interfaces too. (Copy and paste following links in your browser)
NameNode daemon: http://localhost:50070/

mapreduce: http://localhost:8042/

SecondaryNameNode:: http://localhost:50090/status.html
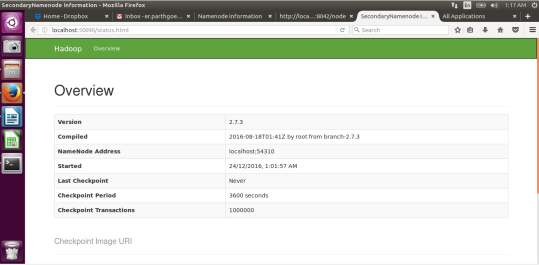
Resource Manager: http://localhost:8088/

Now, we run mapreduce job on our newly created hadoop single node cluster setup.
hduser@parthgoel:/usr/local/hadoop$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 2 5
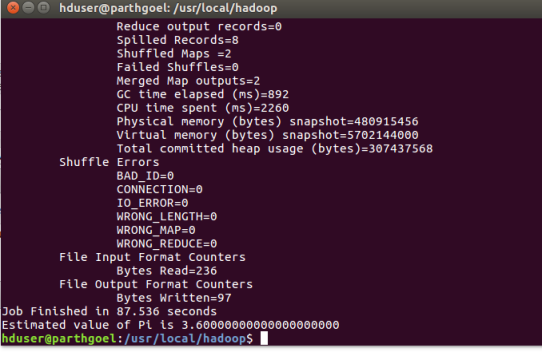
You may like this post:
How to Create Word Count MapReduce Application using Eclipse
NOTE: Whenever we login in Ubuntu, make sure you are in ‘hduser’.
If you are not in hduser, use below command to login in ‘hduser’
$ su hduser

Now you can use all hadoop commands here.
Enjoy..!! Happy Hadooping..!! 🙂
NOTE/error: Once we run any mapreduce program and then you format the namenode, you start all services, it may possible that data node may not get started.
Solution:
Your datanode is not starting because You formatted the namenode again. That means you have cleared the metadata from namenode. Now the files which you have stored for running any mapreduce job are still in the datanode and datanode has no idea where to send the block reports since you formatted the namenode so it will not start.
$ sudo rm -r /usr/local/hadoop_store/hdfs/datanode/current $ hadoop namenode -format $ start-all.sh $ jps
Again Congratulations…!!! Now we can run any hadoop example on this single node cluster. Just make sure you are login in ‘hduser’ because our hadoop setup is available on this dedicated ‘hduser’.
GATE CSE & IT
GATE CSE & IT Materials is uploaded. Visit GATE – CSE & IT tab from Menu or Click.
